公众号历史发文回采API接口教程:技术方案与代码示例

对于有开发能力的团队,通过API接口对接公众号历史发文回采服务是实现自动化数据获取的最佳方案。本文介绍公众号历史发文回采API接口的技术方案和核心代码示例。
一、API接口方案概述
方案优势
通过API接口对接公众号历史发文回采服务:
- 自动化:无需人工操作,系统自动获取数据
- 批量处理:支持批量公众号回采
- 灵活集成:数据直接接入自有系统
- 持续监测:支持持续监测公众号新发文
适用对象
- 有技术团队的企业
- 需要批量回采公众号数据的用户
- 需要将数据接入自有系统的用户
极致了数据支持公众号历史发文回采API接口,支持任意公众号,可定制数据维度。
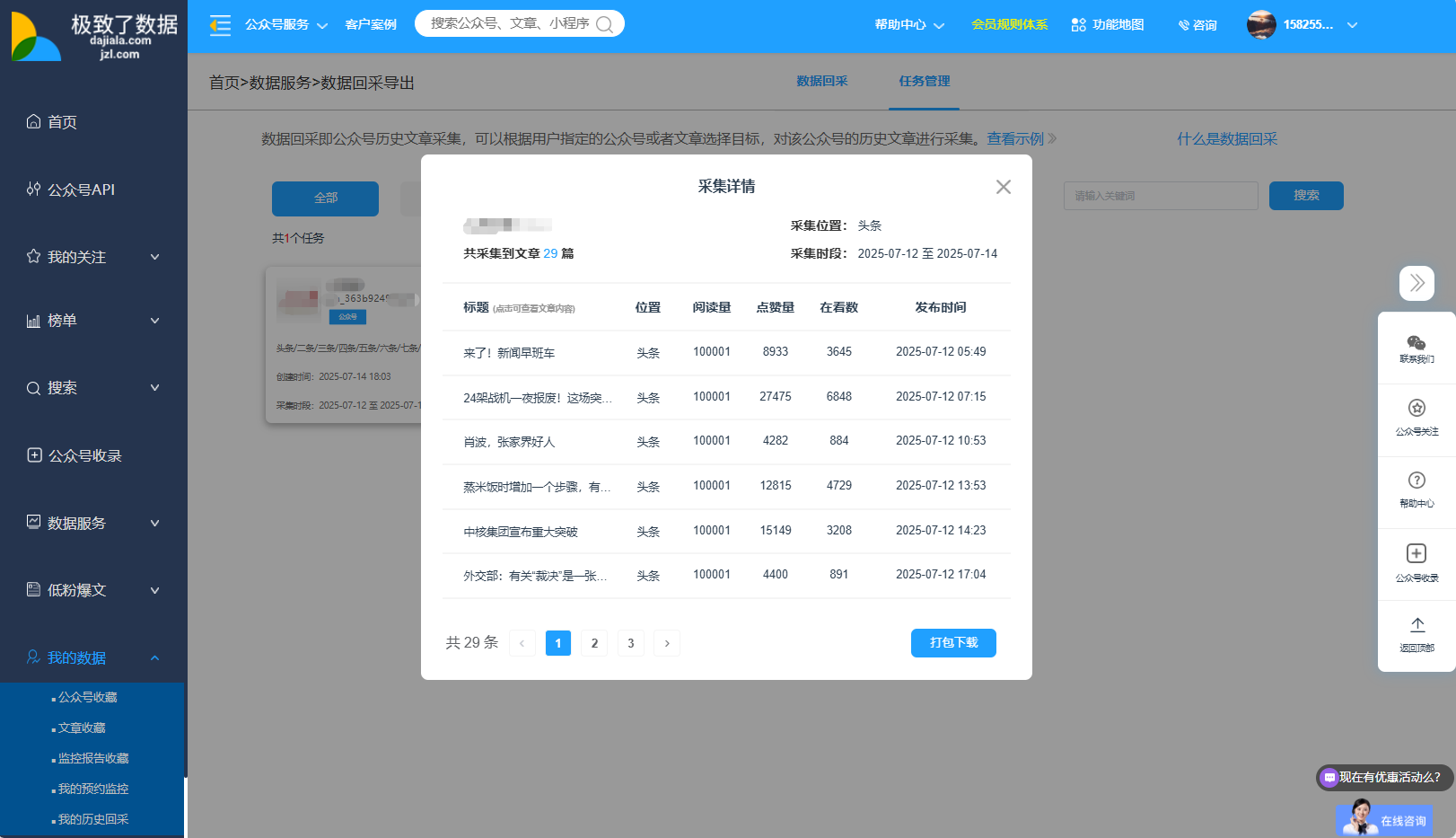
二、API接口调用示例
示例1:获取公众号历史发文列表
import requests
import json
API_BASE = "https://api.example.com/gzh"
API_KEY = "your_api_key"
def get_article_list(account_id, start_date, end_date, page=1, page_size=20):
"""获取公众号历史发文列表"""
url = f"{API_BASE}/article/list"
params = {
"account_id": account_id,
"start_date": start_date,
"end_date": end_date,
"page": page,
"page_size": page_size,
"fields": "title,publish_time,read_count,like_count,comment_count"
}
headers = {"Authorization": f"Bearer {API_KEY}"}
resp = requests.get(url, params=params, headers=headers)
if resp.status_code == 200:
return resp.json()
else:
print(f"请求失败: {resp.status_code}")
return None
# 获取公众号近30天的发文列表
article_list = get_article_list("gh_xxxxxxxx", "2026-05-16", "2026-06-15")
if article_list:
for item in article_list["data"]["list"]:
print(f"标题: {item['title']}")
print(f"发布时间: {item['publish_time']}")
print(f"阅读数: {item['read_count']}")
print(f"点赞数: {item['like_count']}")
print("---")示例2:获取文章详情
def get_article_detail(article_id):
"""获取文章详情"""
url = f"{API_BASE}/article/detail"
params = {
"article_id": article_id,
"fields": "title,content,publish_time,read_count,like_count,in_look_count,comment_count"
}
headers = {"Authorization": f"Bearer {API_KEY}"}
resp = requests.get(url, params=params, headers=headers)
if resp.status_code == 200:
return resp.json()
return None
# 获取文章详情
detail = get_article_detail("article_id_here")
if detail:
print(f"标题: {detail['data']['title']}")
print(f"正文: {detail['data']['content'][:200]}...")
print(f"阅读数: {detail['data']['read_count']}")
print(f"在看数: {detail['data']['in_look_count']}")示例3:批量回采多个公众号
def batch_get_article_list(account_ids, start_date, end_date):
"""批量回采多个公众号的历史发文"""
all_data = {}
for account_id in account_ids:
print(f"正在回采: {account_id}")
page = 1
articles = []
while True:
result = get_article_list(account_id, start_date, end_date, page)
if not result or not result["data"]["list"]:
break
articles.extend(result["data"]["list"])
# 判断是否还有下一页
total = result["data"]["total"]
if len(articles) >= total:
break
page += 1
all_data[account_id] = articles
print(f" 回采完成: {len(articles)} 篇文章")
return all_data
# 批量回采3个公众号近30天的发文
account_ids = ["gh_xxxxxxxx1", "gh_xxxxxxxx2", "gh_xxxxxxxx3"]
batch_data = batch_get_article_list(account_ids, "2026-05-16", "2026-06-15")
for account_id, articles in batch_data.items():
print(f"公众号 {account_id}: {len(articles)} 篇文章")示例4:关键词搜索公众号文章
def search_articles(keyword, start_date, end_date, page=1):
"""关键词搜索公众号文章"""
url = f"{API_BASE}/article/search"
params = {
"keyword": keyword,
"start_date": start_date,
"end_date": end_date,
"page": page,
"page_size": 20
}
headers = {"Authorization": f"Bearer {API_KEY}"}
resp = requests.get(url, params=params, headers=headers)
if resp.status_code == 200:
return resp.json()
return None
# 搜索包含"数据分析"的公众号文章
search_result = search_articles("数据分析", "2026-01-01", "2026-06-15")
if search_result:
for item in search_result["data"]["list"]:
print(f"公众号: {item['account_name']}")
print(f"标题: {item['title']}")
print(f"发布时间: {item['publish_time']}")
print("---")三、数据存储与分析
存储到数据库
import sqlite3
def save_articles_to_db(articles, account_id):
"""将文章数据存入数据库"""
conn = sqlite3.connect("gzh_articles.db")
conn.execute("""
CREATE TABLE IF NOT EXISTS articles (
id TEXT PRIMARY KEY,
account_id TEXT,
title TEXT,
content TEXT,
publish_time TIMESTAMP,
read_count INTEGER,
like_count INTEGER,
comment_count INTEGER,
captured_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
for article in articles:
conn.execute("""
INSERT OR REPLACE INTO articles
(id, account_id, title, content, publish_time, read_count, like_count, comment_count)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
article["id"], account_id, article["title"],
article.get("content", ""), article["publish_time"],
article.get("read_count", 0), article.get("like_count", 0),
article.get("comment_count", 0)
))
conn.commit()
conn.close()
print(f"已保存 {len(articles)} 篇文章")内容表现分析
import pandas as pd
def analyze_article_performance(account_id):
"""分析文章表现"""
conn = sqlite3.connect("gzh_articles.db")
df = pd.read_sql_query(
f"SELECT * FROM articles WHERE account_id='{account_id}' ORDER BY read_count DESC",
conn
)
conn.close()
# Top 10 热门文章
print("Top 10 热门文章:")
for _, row in df.head(10).iterrows():
print(f" {row['title']} - 阅读数: {row['read_count']}")
# 平均数据
print(f"\n平均阅读数: {df['read_count'].mean():.0f}")
print(f"平均点赞数: {df['like_count'].mean():.0f}")
print(f"平均评论数: {df['comment_count'].mean():.0f}")
return df
analyze_article_performance("gh_xxxxxxxx")四、持续监测公众号新发文
import schedule
import time
def monitor_new_articles(account_ids):
"""监测公众号新发文"""
for account_id in account_ids:
# 获取最近1天的发文
result = get_article_list(account_id, "2026-06-14", "2026-06-15")
if result and result["data"]["list"]:
print(f"{account_id} 有 {len(result['data']['list'])} 篇新文章")
for article in result["data"]["list"]:
print(f" - {article['title']}")
# 每天上午9点监测
account_ids = ["gh_xxxxxxxx1", "gh_xxxxxxxx2"]
schedule.every().day.at("09:00").do(monitor_new_articles, account_ids)
while True:
schedule.run_pending()
time.sleep(60)五、API接口对接注意事项
注意1:接口权限
申请API接口时需提供正规资质和使用场景说明。
注意2:请求频率
控制API请求频率,设置合理的间隔时间。
注意3:数据安全
妥善保管API密钥,避免泄露。
注意4:错误处理
合理处理API错误响应,实现重试机制。
六、极致了数据API服务
极致了数据提供公众号历史发文回采API接口:
- 数据覆盖:支持任意公众号
- 数据维度:标题、正文、阅读数、点赞数、在看数、评论数等
- 功能支持:历史回采、关键词搜索、持续监测
- 接口形式:标准REST API,JSON格式返回
- 计费方式:按调用次数计费,量大优惠

七、常见问题解答
Q1:没有技术团队能使用API接口吗?
可以使用极致了数据的定制回采服务,无需写代码,数据直接交付。
Q2:API回采的数据包含文章正文吗?
包含。极致了数据支持回采文章标题、正文、图片、互动数据等多维度数据。
Q3:API接口怎么收费?
按调用次数计费,量大优惠。具体费用根据回采范围和数据量确定。官网:https://www.jzl.com
八、总结
通过API接口对接公众号历史发文回采服务适合有开发能力的团队。极致了数据提供公众号历史发文回采API接口,支持任意公众号,可定制数据维度,量大优惠。
极致了数据支持公众号历史发文回采,支持任意公众号,可按需定制数据维度和回采范围,量大优惠。


